
Hi folks,
silently been on this forum for some 8 years, switched on my QL last time in 2015. Been coding since the '80s as a pastime, mostly C/C++/python on linux, all sort of useless stuff from 3d libraries for 3d games in console mode, to new languages (both interpreted and compiled). Re-discovered QPC2 recently and started porting programs I recovered from my QL floppies and... modernising them a bit.
My Mandelbrot generator from 1989 was running in mode 8 (screenshot from QPC2). Worked on it a bit and ported to QPC2 with high-colour, supersampling (up to 8x8), rectangle checking (considerable speedup on homogeneous areas), bookmarks, auto iterations, choice of colouring algorythms, advancement bar with ETA, etc.
Compiled with Turbo, not much of a change not sure whether SBASIC SMSQ/E on QPC2 is very fast or there are better compilers than Turbo... can't force myself to write the inner Mandelbrot loop in asm... so it's still obviously slow, beign a SBASIC program, despite heavy optimization (including now a good +10% speed by switching to GOSUB vs FuNction as a function call seems to be taking more time, likely in allocating stack for LOCal variables and dealing with parameters and the RETurn value). Yet oddly satisfying to me... watching those beatiful shapes being painted in front of me. Not much of a point making it some % faster, when any iPAD with Apple M1 can animate Mandelbrot in real time.
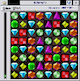
It's still in Italian, not sure it would be of interest to anybody... meanwhile here's a screenshot from V5.00, coming 34 years after V1.01. [edit]: it still works in MODE 4 at 512x256, with 22 colors simulated with stipples. The image below is calculated with 3x3 supersampling, that makes the picture more "readable" (less noise near the boundary of the Mandelbrot set).
re-discovering the QL... mandelbrot 1989-2023
re-discovering the QL... mandelbrot 1989-2023
- Attachments
-
-
- Screenshot 2023-03-18 134812.png (6.1 KiB) Viewed 3212 times
-
-
Derek_Stewart
- Font of All Knowledge
- Posts: 3975
- Joined: Mon Dec 20, 2010 11:40 am
- Location: Sunny Runcorn, Cheshire, UK
Re: re-discovering the QL... mandelbrot 1989-2023
Hi
The Mandelbrot sets look great.
I remember seeing Gerge Gwilt do this type of thing in assembler, really slick.
I can not SBASIC being faster thsn Turbo compiled. But it might fun to see the difference.
The Mandelbrot sets look great.
I remember seeing Gerge Gwilt do this type of thing in assembler, really slick.
I can not SBASIC being faster thsn Turbo compiled. But it might fun to see the difference.
Regards,
Derek
Derek
Re: re-discovering the QL... mandelbrot 1989-2023
SBASIC is really blazingly fast compared to SuperBASIC - Turbo will only be able to generate a very moderate speed increase. So what you see is not Turbo being inept, but rather SBASIC close to perfect...Derek_Stewart wrote: ↑Sat Mar 18, 2023 3:59 pm Hi
The Mandelbrot sets look great.
I remember seeing Gerge Gwilt do this type of thing in assembler, really slick.
I can not SBASIC being faster thsn Turbo compiled. But it might fun to see the difference.
ʎɐqǝ ɯoɹɟ ǝq oʇ ƃuᴉoƃ ʇou sᴉ pɹɐoqʎǝʞ ʇxǝu ʎɯ 'ɹɐǝp ɥO
-
Derek_Stewart
- Font of All Knowledge
- Posts: 3975
- Joined: Mon Dec 20, 2010 11:40 am
- Location: Sunny Runcorn, Cheshire, UK
Re: re-discovering the QL... mandelbrot 1989-2023
Hi,
Apart from my spelling and grammar errors, I was hoping for a comparison of SuperBASIC and SBASIC to Turbo compiled when performing Mandelbrot Set generation.
Not SuperBASIC against SBASIC, it is well known that SBASIC is faster, can execute basic programmes. Whereas QDOS requires Minerva v1.90 owards to Multibasic.
Apart from my spelling and grammar errors, I was hoping for a comparison of SuperBASIC and SBASIC to Turbo compiled when performing Mandelbrot Set generation.
Not SuperBASIC against SBASIC, it is well known that SBASIC is faster, can execute basic programmes. Whereas QDOS requires Minerva v1.90 owards to Multibasic.
Regards,
Derek
Derek
Re: re-discovering the QL... mandelbrot 1989-2023
quick comparison: basic set, 960 x 510 points, 512 iterations, no rectangle checking (all points calculated individually), SBASIC = 88s, Turbo compiled code = 40sDerek_Stewart wrote: ↑Sun Mar 19, 2023 8:39 am Hi,
Apart from my spelling and grammar errors, I was hoping for a comparison of SuperBASIC and SBASIC to Turbo compiled when performing Mandelbrot Set generation.
Not SuperBASIC against SBASIC, it is well known that SBASIC is faster, can execute basic programmes. Whereas QDOS requires Minerva v1.90 owards to Multibasic.
same as above with 1024 iterations, 480 x 255 points, SBASIC = 40s, Turbo = 18s
So it would seem Turbo is about 55% faster than SBASIC on my particular code. The SBASIC core iteration uses well-known formulas to minimise the cost of FP operations. I think that the difference between SBASIC and Turbo on those few Fp operations would be minimal, as the FP operations time would be predominant over interpreter time, while the one that seems to take much longer in SBASIC is the IF evaluation to exit the loop if iterations reach the max iteration limit. e.g. if one adds the convergence detection (whether the iteration has converged to a point, which means you're in the set anyway and don't need to wait until max iterations), the cost of the extra IF to exit the loop takes more time SBASIC than the time saved on iterations in the set, unless most of the points in the picture are in the set.
Also, I found that there's a 10% cost in Functions vs GOSUB, likely due to stack operations on FuNction entry/exit and LOCal variable allocation.
BTW anyone remembers where QDOS FP operations in assembler are documented? was it the Technical guide? not sure I'll do it but it would be nice to try and code the mandel loop in assembler

Re: re-discovering the QL... mandelbrot 1989-2023
Ciao Roberto,
and welcome back ti the QL scene!
Your Mandelbrot program looks very interesting, I'm looking forward to try it with my QLs
and welcome back ti the QL scene!
Your Mandelbrot program looks very interesting, I'm looking forward to try it with my QLs
Re: re-discovering the QL... mandelbrot 1989-2023
Hi there. While moving with family to a new flat, not much time these days... thought I would put the program on a public Bitbucket repo, you can download it from there https://bitbucket.org/mrzap000/mandel/src/master/
Re: re-discovering the QL... mandelbrot 1989-2023
Decided to rediscover the 68k assembly language and try to implement a mandelbrot code iteration in asm with fixed point integers. 1st go used 16bit due to the 68k 16-bit MULS/MULU limitation (16bit operands). Limited to 11 bits after decimal point. 2nd go implemented a 64bit multiplication with 32bit operands. Works up to 26 bits after decimal point. Limited magnification and the 64bit product is significantly slower on QPC2. With 16/32bit integer math it is fast enough, even in SBASIC, to animate in low resolution in real time. The SBASIC program calls the Mandelbrot iteration via CALL address,Cre,Cim where Cre=(C real)<<precision etc.
will post link to video of animation when I have some time
sample asm code from the 16/32 bit version, unoptimized and ugly, followed by sample program (with test procedures)
using CST Quanta ASM
SBASIC program
will post link to video of animation when I have some time
sample asm code from the 16/32 bit version, unoptimized and ugly, followed by sample program (with test procedures)
Code: Select all
vcim equ 4
vcre equ 8
vrad equ 12
vrad2 equ 16
vfac equ 20
section code
bra start
nop
maxiter dc.w 200
dc.w 0
dc.l 0
dc.l 0
dc.l 4
dc.l 0
dc.w 11
nop
start
lea maxiter,a1
moveq #0,d0 m%
clr.l d3 zresq
clr.l d4 zimsq
clr.l d5 zre
clr.l d6 zim
move.l d1,vcre(a1)
move.l d2,vcim(a1)
clr.l d1
move.w vfac(a1),d1
clr.l d2
move.l vrad(a1),d2
lsl.l d1,d2
move.l d2,vrad2(a1)
loop1
move.l d5,d7
lsl.l #1,d7 zre*2
muls d6,d7 zim*zre*2
lsr.l d1,d7
add.l vcim(a1),d7 cim+zim*zre*2
move.l d7,d6 =zim
move.l vcre(a1),d7 cre
add.l d3,d7 zresq+cre
sub.l d4,d7 zresq+cre-zimsq
move.l d7,d5 =zre
* move.w d5,d7 zre
muls d5,d7 zre*zre
lsr.l d1,d7
move.l d7,d3 =zresq
move.l d6,d7 zim
muls d6,d7 zim*zim
lsr.l d1,d7
move.l d7,d4 =zimsq
addq.w #1,d0
cmp.w (a1),d0
ble jump1
clr.l d0
bra exit
jump1
move.l d3,d7
add.l d4,d7
cmp.l vrad2(a1),d7
ble loop1
exit
move.w d0,2(a1)
clr.l d0
rts
end
SBASIC program
Code: Select all
100 DEFine PROCedure init(f$)
105 IF f$="":fb$="win2_test":ELSE fb$=f$
110 EXEP qd;fb$&"_asm"
120 a=ALCHP(1000)
130 fact=11:f=2^fact
140 END DEFine
150 DEFine PROCedure setfact(f1)
160 fact=f1:f=2^f1
170 END DEFine
180 DEFine PROCedure asm
190 EXEP dev2_qmac;fb$
200 PAUSE
210 EXEP dev2_qlink;fb$
220 END DEFine
230 DEFine PROCedure ld(a)
240 LBYTES win2_test_bin,a
250 END DEFine
260 DEFine PROCedure dump(a)
270 LOCal i
280 FOR i=a TO a+136 STEP 2:PRINT HEX$(PEEK_W(i),16)!!
290 PRINT
300 END DEFine
310 DEFine FuNction mandel(cim,cre)
320 CALL a,INT(cre*f),INT(cim*f)
330 RETurn PEEK_W(a+8)
340 END DEFine
350 DEFine PROCedure drawmandel(iter%,bs%,pixels,x,y,dx,dy)
360 LOCal x%,y%,m,i,j,i2%,stx,sty,infx,infy,supx,supy,xs%,ys%
362 IF dx=0 OR dy=0:infx=-2:supx=1:infy=-1.5:supy=1.5:ELSE infx=x:infy=y:supx=x+dx:supy=y+dy
363 IF bs%=0:bs%=2
364 IF pixels=0:pixels=150
365 xs%=bs%:ys%=bs%
370 stx=(supx-infx)/pixels*xs%:sty=(supy-infy)/pixels*ys%
380 POKE_W a+6,iter%
390 REMark POKE_W a+26,fact
400 x%=0
410 FOR i=infx TO supx STEP stx
420 y%=0
430 i2=INT(i*f)
440 FOR j=infy TO supy STEP sty
450 CALL a,i2,INT(j*f)
460 m=(PEEK_W(a+8)*3)MOD 256
470 BLOCK xs%,ys%,x%,y%,m*3+m*512+m*65536:y%=y%+ys%
480 END FOR j
490 x%=x%+xs%
500 END FOR i
510 END DEFine
520 :
522 fb$="win2_test"
525 COLOUR_24
530 a=ALCHP(200)
540 ld a
550 setfact 10
560 drawmandel 200
570 RECHP a
580 PAUSE
790 DEFine PROCedure animate
795 LOCal i,d
800 FOR i=1 TO 7 STEP 7E-2:d=10/2^i:drawmandel 100,3,200,-1.03+(.4-d)/2,-.4+(.4-d)/2,d,d
810 END DEFine
- Attachments
-
-
NormanDunbar

- Forum Moderator
- Posts: 2281
- Joined: Tue Dec 14, 2010 9:04 am
- Location: Leeds, West Yorkshire, UK
- Contact:
Re: re-discovering the QL... mandelbrot 1989-2023
If you need/want a 32 bit by 32 bit multiply routine, then Issue 11 of the extremely random eMagazine on Assembly Programming has on which I wrote and is free for all to use. You can get the PDF and code files at https://github.com/NormanDunbar/QLAssem ... g/Issue_11 if you wish.
Your mandlebrot set image looks excellent.
Cheers,
Norm.
Your mandlebrot set image looks excellent.
Cheers,
Norm.
Why do they put lightning conductors on churches?
Author of Arduino Software Internals
Author of Arduino Interrupts
No longer on Twitter, find me on https://mastodon.scot/@NormanDunbar.
Author of Arduino Software Internals
Author of Arduino Interrupts
No longer on Twitter, find me on https://mastodon.scot/@NormanDunbar.
Re: re-discovering the QL... mandelbrot 1989-2023
can't thank you enough, I used to love programming in 68k assembler back in the 80's but I'm soo rusty now... great reading, will go through your eMagazine for sure!!NormanDunbar wrote: ↑Fri Mar 31, 2023 7:43 pm If you need/want a 32 bit by 32 bit multiply routine, then Issue 11 of the extremely random eMagazine on Assembly Programming has on which I wrote and is free for all to use. You can get the PDF and code files at https://github.com/NormanDunbar/QLAssem ... g/Issue_11 if you wish.
btw, I gave it a go myself, based on some theory I found on the web, but the resulting set gets fuzzy on high magnification instead of blockly, which is what you'd expect when reaching the limits of the 26-bit precision.. I guess I'm doing something wrong, I'll look into yours, thank you!
Code: Select all
*
* subroutine to multiply two 32 bit integers
* d1,d2 operands
* result in d2
* vfac(a1) holds the precision in bits (i.e. 26)
* the comments assume AB CD are two 32bit integers holding fixed-point numbers with vfac(a1) bits of precision
* the most significant longword is discarded, we only keep the least significant longword as a result for our mandelbrot set as all other calculations are on 32 bits
mul32
move.w d1,d3 b
move.w d2,d4 d
mulu d3,d4 b*d
move.l d4,d5 b*d
move.w d1,d3 b
swap d2
move.w d2,d4 c
mulu d3,d4 b*c
move.l d4,d6 b*c
swap d1
move.w d1,d3 a
swap d2
move.w d2,d4 d
mulu d3,d4 a*d
add.l d4,d6 b*c+a*d
* moveq #16,d3
swap d6
* lsl.l d3,d6 (b*c+a*d)<<16
move.w d5,d6 (b*c+a*d)<<16 + b*d
move.w d1,d3 a
swap d2
move.w d2,d4 c
muls d3,d4 a*c
* now lower 32bit in d6, higher 32 bit in d4, must shift right
move.l vfac(a1),d3
move.l d4,d5 high 32 in d5
ror.l d3,d5 rotate right by factor
move.l d4,d2 high longword in d2
lsr.l d3,d2 shift right by factor - d2 is now the light 32
eor.l d2,d5 now in d5 just the left bits that must go to the lower 32
lsr.l d3,d6
or.l d5,d6 now in d6 the full low 32 shifted by d3
move.l d6,d2 we just take the lower 32 as a return value
rts